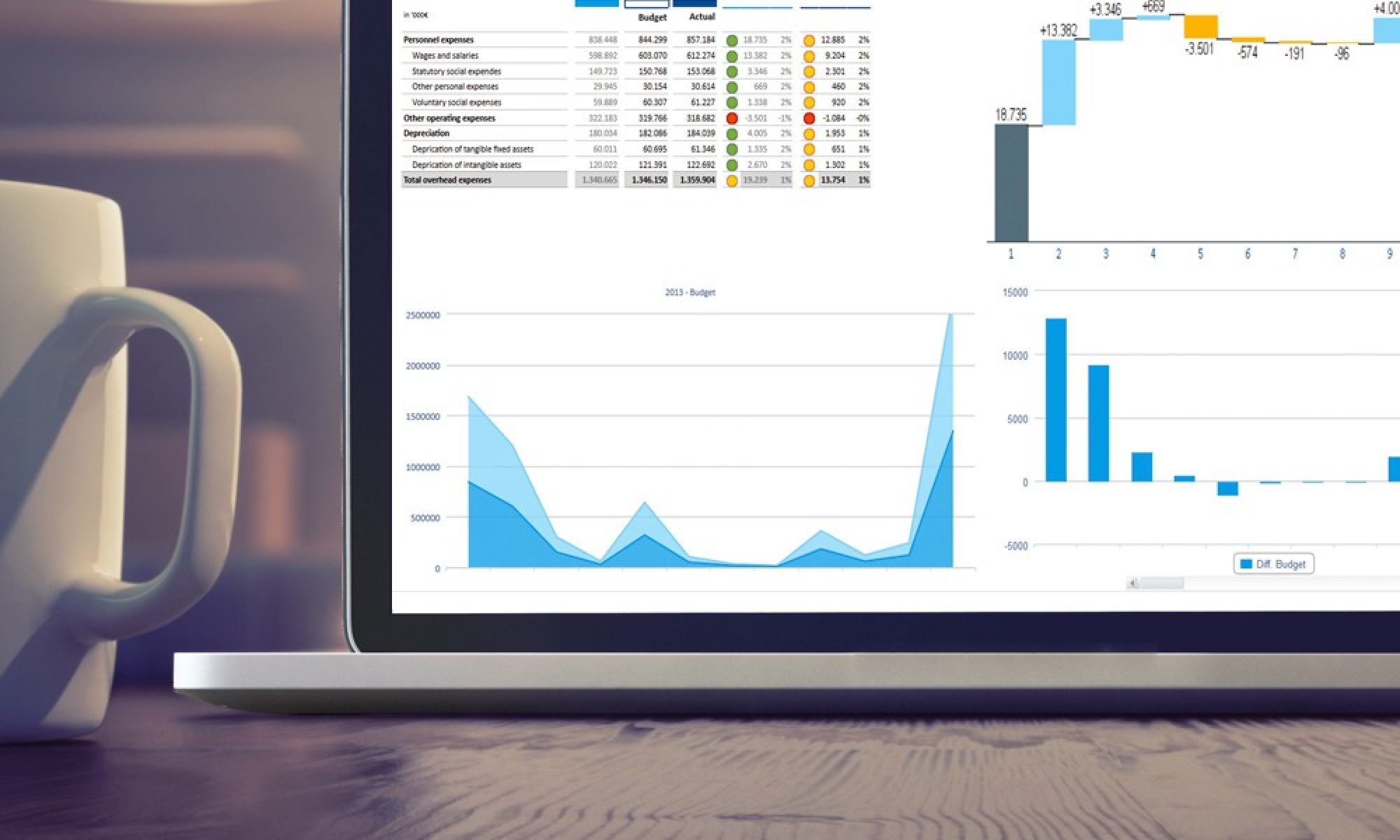
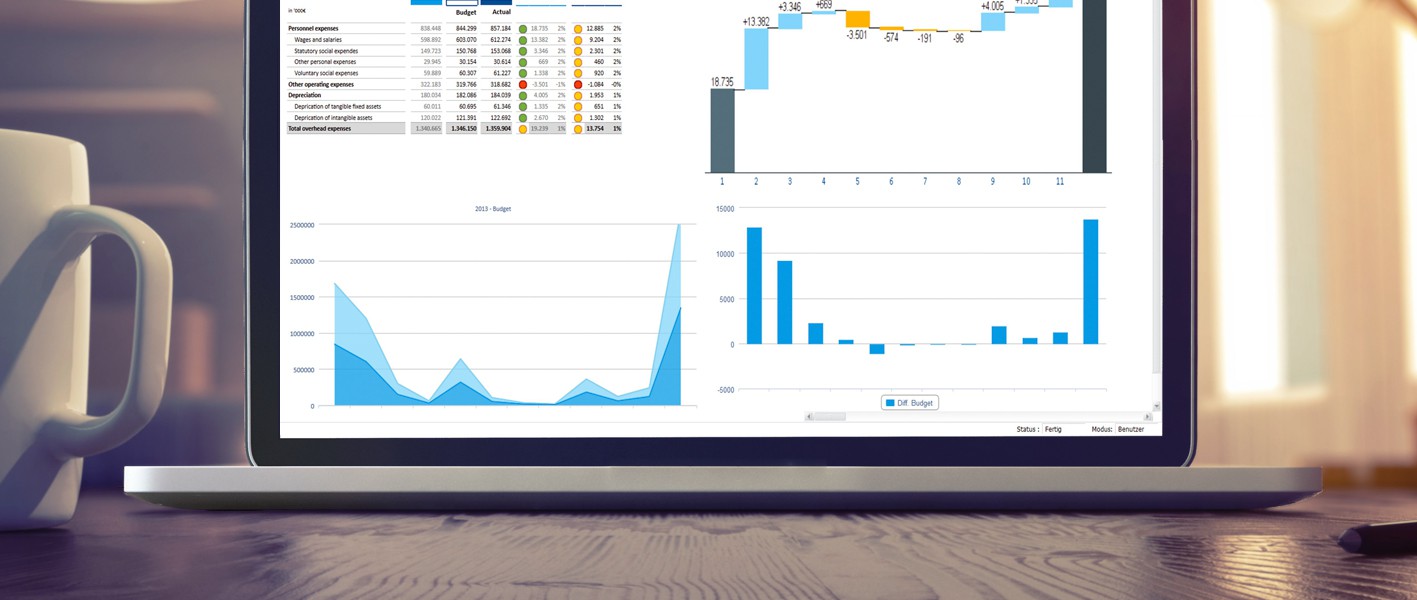
Jedox ist ein Business-Intelligence Tool, das auf Basis von Daten-Würfeln die dynamische Auswertung von Geschäftsdaten unterstützt.
Im Laufe der Projekte bin ich immer wieder auf das Problem gestoßen, dass Daten sowohl aus den Vorsystemen per ETL-Prozess abgeholt werden und gleichzeitig manuelle Eingaben für die gleichen Daten von Nutzern vorgenommen wurden. Dies ist zum Beispiel dann notwendig, wenn Forecasts für die Produktion mit den aktuellen Erkenntnissen abgeglichen werden müssen.
Konflikte zwischen Vorsystem und Datencubes
Mit diesem Prozess ergeben sich verschiedene Konflikte:
- Die manuellen Eingaben werden vom ETL wieder überschrieben, um eine konsistente Datengrundlage zu gewährlisten.
- Die manuellen Eingaben lassen sich schwer nachvollziehen. Es ist kaum noch möglich zu erkennen, ob Änderungen vom System oder durch manuelle Korrektur entstanden sind.
- Die Definition, welche Daten überschrieben werden sollen und welche nicht, ist nicht immer eindeutig.
Dies hat unterschiedliche Gründe. Zunächst ist Jedox kein Data Warehouse und damit eigentlich nicht für die Datenhaltung vorgesehen. Diese muss bereits an anderer Stelle gewährleistet werden.
Durch die Write-Back-Funktionalität widerspricht Jedox den Single-Point-of-Truth-Ansatz. Nutzer können nachträglich Daten eingeben, die nicht mehr im Vorsystem abgelegt werden. Jedox rutscht damit vom reinen Analyse-Werkzeug auch in die Position eines Quellsystems, dessen neue Informationen genau genommen auch wieder im Data Warehouse abgespeichert werden müssten.
Ein möglicher Lösungsansatz
Um den Konflikt aufzulösen gibt es verschiedene Lösungsansätze. Da unsere Projekte im Normalfall keine „idealen“ DWH-Architekturen aufweisen, stellt sich das Problem vom Single-Point of Truth nur bedingt.
Der Jedox-ETL übernimmt hier direkt die Zusammenführung aus den operativen Vorsystemen und schafft damit erstmalig eine Form von zentraler Datenhaltung.
Um nun die operativen Daten der Vorsysteme und die Nutzereingaben zu trennen, setzen wir auf gespiegelte Cubes. Die Daten der Vorsysteme werden per ETL in eigene Data-Cubes geladen, auf die anschließend von einem gespiegelten Cube über Regeln zugegriffen werden. In diesem können nun auch gefahrlos Nutzereingaben zugelassen werden.
Dadurch lässt sich auch vermeiden, dass schreibberechtigte Nutzer ausversehen Änderungen an den Rohdaten vornehmen.
Zusätzlich wird sichergestellt, dass Nutzereingaben stets getrennt von den Systemdaten behandelt werden und durch den ETL nicht ausversehen durch ein Update überschrieben werden.